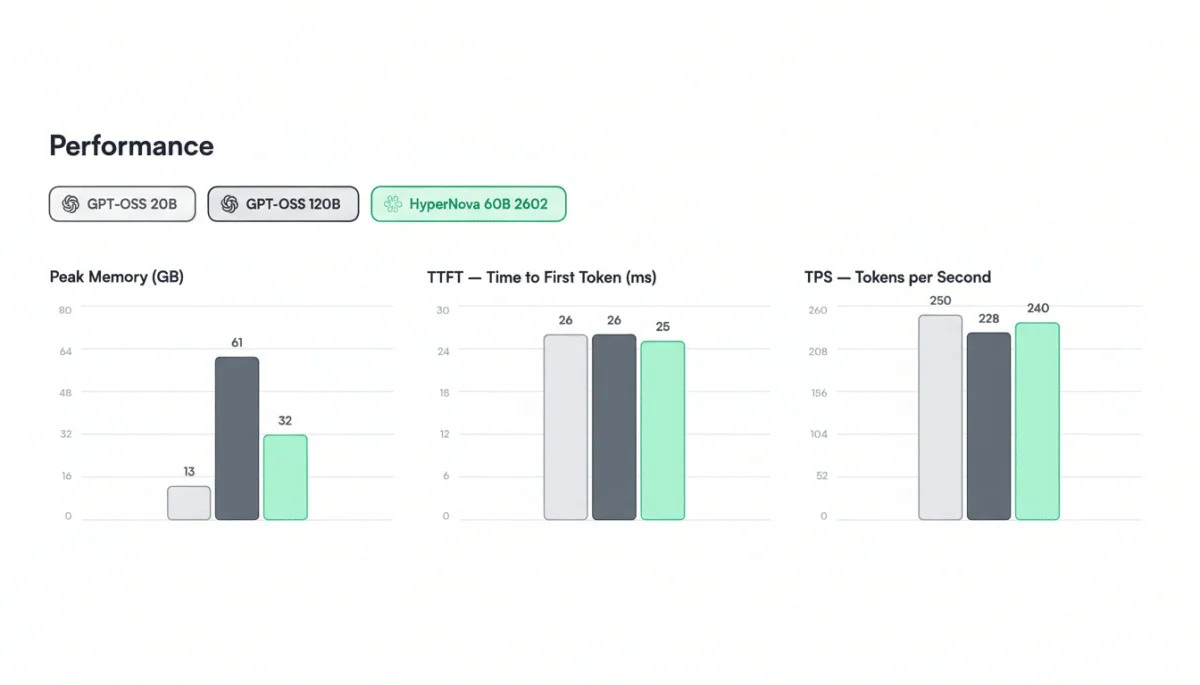

The launch of the HyperNova 60B 2602 from Spanish startup Multiverse Computing signifies a noteworthy advancement in AI technology, with a focus on reducing operational costs and resource demands. This newly unveiled model, accessible to developers via Hugging Face, leverages CompactifAI technology to deliver near-frontier performance while significantly minimizing its memory footprint to about 32GB, nearly half that of its predecessor, OpenAI's gpt-oss-120B.
With the 2602 upgrade, improvements in tool calling and agentic coding are aimed at tackling the costly workloads traditionally associated with larger models. This innovation allows AI engineers to assess the effectiveness of compressed models in achieving production-grade accuracy, a critical factor for enterprises concerned with hardware and latency issues.
Multiverse plans to introduce more compressed models over the year, targeting various tasks including code synthesis and structured extraction. The financial advantages of model compression are significant, as they can lead to lower inference costs, higher tokens-per-second rates, and improved resource utilization, all pivotal for organizations managing extensive AI operations.